Approximation
- 근사치는 참값과 비슷한 True value와 비슷한 값을 의미한다.
- True value를 계산하기 힘들 때 approximation을 사용한다. 대표적으로 반올림이 있다.
Interpolation vs Approximation
보간법은 점으로 표현된 데이터를 선으로 잇는 방식으로 값을 예측하는 방법이다. 반면, 근사법은 전체 데이터의 통계에 기반해 가장 높은 확률을 지닌 값을 예측하는 방법이다.
보간법은 이상치에 큰 영향을 받기 때문에, 주어진 데이터의 신뢰도가 높은 경우에 사용한다. 반면에 근사법은 이상치에 Robust하다.
Regression
회귀 분석이란 독립변수와 종속변수 간의 관계를 통계적으로 모델링하는 기법이다.
데이터 + 결과값으로 알고리즘을 구한다는 점에서 머신러닝과 흡사하다. 이러한 특성 때문에 딥러닝 과정을 선형회귀에 빗대어 자주 설명한다.
선형회귀에서 선형이라는 단어는 여러 방식으로 해석된다. polynominal regression 문제 역시 선형으로 해석한다.
Regression 모델의 차수가 높아질수록 주어진 dataset에 fit하지만, 그 정도가 과할 경우 overfitting이 발생한다.
선형 회귀에서 모델을 훈련시키는 두 가지 방법
- 직접 계산할 수 있는 공식을 사용해서 train set에 가장 잘 맞는 모델 파라미터를 구하는 방법
- Gradient Desenct를 활용한 반복적 최적화를 통해 모델 파라미터를 조금씩 바꾸며 비용함수를 최소화 하는 방법
해석적으로 해를 구하는 법
Linear Regression은 손실 함수를 미분해 극소점을 찾아 최적화를 할 수 있다. 즉 결과를 바로 얻을 수 있는 수학공식을 이용하는 것이다. 이때 사용되는 식을 정규 방정식(normal equation)이라고 한다.
경사하강법
경사하강법의 종류로는 3가지가 있다.
- 배치 경사하강법: 전체 훈련 세트의 오차를 통해 기울기 계산
- 확률적 경사하강법: 훈련 세트에서 무작위로 선택된 하나의 요소로 기울기 계산
- 미니배치 경사하강법: 훈련 세트에서 무작위로 선택된 N개의 요소로 기울기 계산
3가지 방식의 차이를 간략하게 수식화하면 아래와 같이 표현할 수 있다.
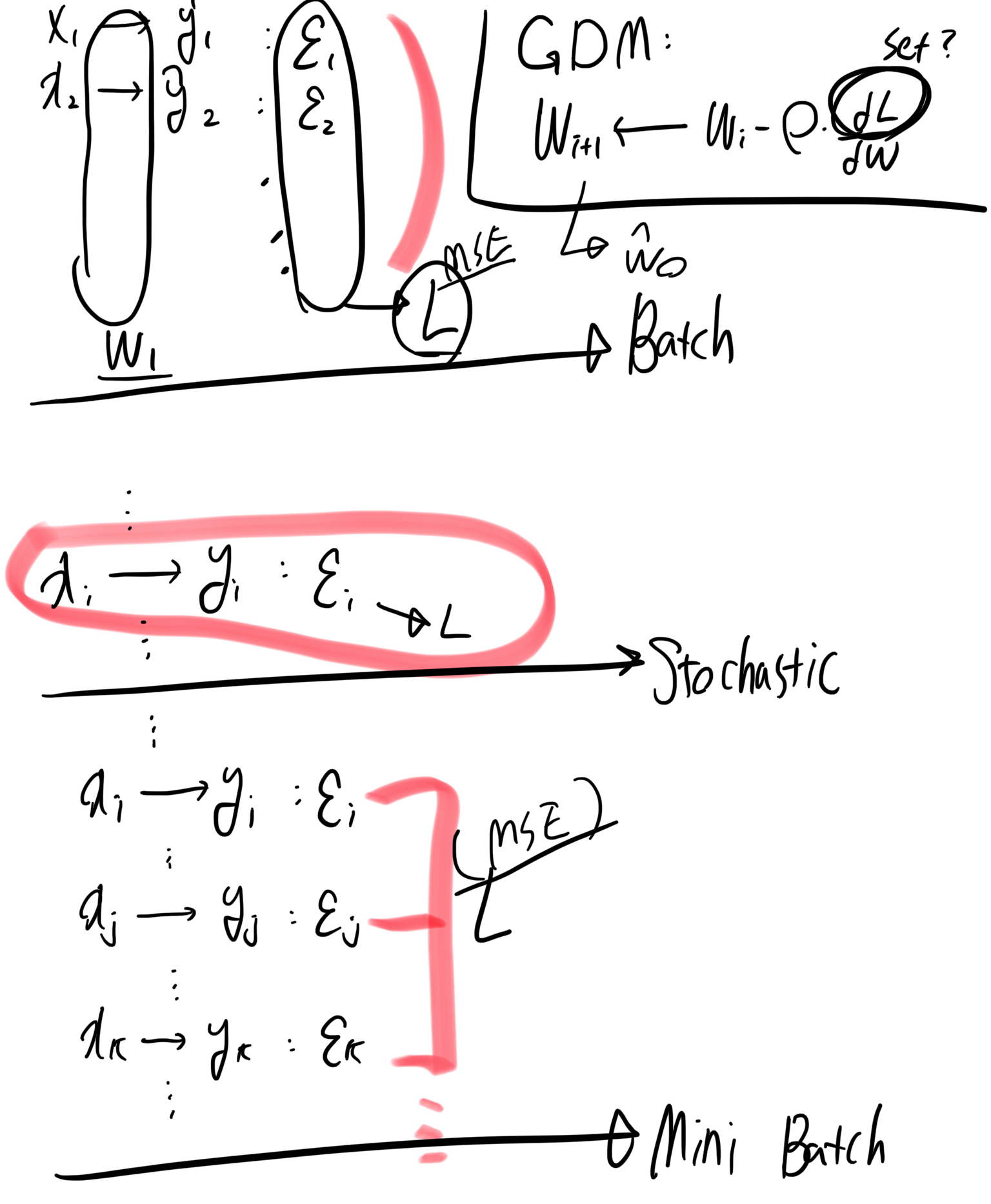
확률적 경사 하강법 Stochastic
- 느린 배치 경사 하강법을 보안하기 위해서 등장
- 하나의 샘플만을 처리하기 때문에 불안정하다
- 최소값에 다다를 때까지 요동치면서 평균적으로 계산한다
- 최소값에 안착하지 못한다
- 빠르게 학습상황을 파악할 수 있다
미니배치 경사 하강법
- 일반 방법에 비해서 행렬 연산에 최적화 되어 GPU를 사용했을 때 상당히 빠른 속도로 계산할 수 있다
- 확률적 경사 하강법이 하나의 입력set을 가지고 cost를 계산하는 것에 비해 N개의 set를 이용하기 때문에 더욱 안정적으로 최소값에 접근한다.
Polynominal Regression
신기하게도 비선형 데이터를 학습하는데 선형 모델을 사용할 수 있다. 이렇게 하는 간단한 방법은 각 특성의 거듭제곱을 새로운 특성으로 추가하고, 이 확장된 특성을 포함한 데이터셋에 선형 모델을 훈련시키는 것이다.
from sklearn.preprocessing import PolynomialFeatures
poly_features = PolynomialFeatures(degree=2, include_bias=False)위 코드의 PolynominalFeatures의 차수를 높여주면 데이터셋에 더욱 다가가게 구불구불한 모양을 가진다. 이러한 고차 다항 회기 모델은 훈련 데이터셋에 과대적합(over-fitting)된다.
모델의 일반화 성능을 추정하기 위해서는 교차 검증(cross-validation)을 사용해야 한다. 즉 훈련 데이터와 검증 데이터를 나누어 교차검증을 통해 과대적합 혹은 과소적합 여부를 판단해야 한다.
Learning Curve
이 그래프는 훈련 세트와 검증 세트의 모델 성능을 훈련 반복의 함수로 나타낸다.
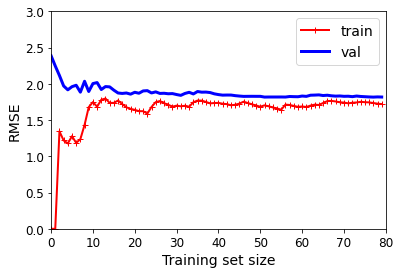
과소적합된 모델의 전형적인 모습입니다. 두 곡선이 수평한 구간을 만들고 꽤 높은 오차에서 매우 가까이 근접해 있다.
과소적합을 해소하기 위해서는 훈련 샘플을 추가하거나 더 복잡한 모델을 사용해야 한다.
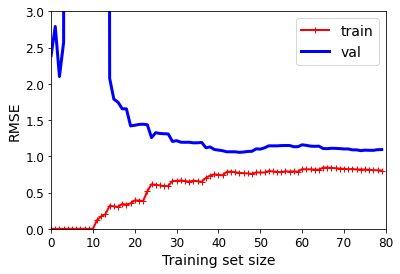
이 학습 곡선은 이전과 비슷해 보이지만 두 가지 매우 중요한 차이점이 있습니다.
- 훈련 데이터의 오차가 선형 회귀 모델보다 훨씬 낮습니다.
- 과대적합 모델을 개선하는 한 가지 방법은 검증 오차가 훈련 오차에 근접할 때까지 더 많은 훈련 데이터를 추가하는 것이다.
'Deep Learning' 카테고리의 다른 글
| 0206 Vanishing / Exploding Gradient (0) | 2022.04.17 |
|---|---|
| 0204 Cross Validation / Confusion Matrix (0) | 2022.04.12 |
| 0203 Logistic Regression (0) | 2022.04.12 |
| 0202 Regularized Linear Models (0) | 2022.04.12 |
| 딥러닝 01::퍼셉트론에서 손실함수 까지 (0) | 2022.03.22 |


