로지스틱 회귀
회귀 알고리즘은 분류 모델로 사용할 수 있다. 특히 로지스틱 회귀는 샘플이 특정 클래스에 속할 확률을 추정하는데 널리 사용된다. 대표적으로 Binary classifier가 이에 해당된다.
로지스틱 회귀의 작동방식 역시 선형 회귀 모델과 같이 가중치 합을 계산한 다음 편향을 더한다. 다만 선형회귀처럼 결과를 바로 출력하지 않고 결과값의 logistic을 출력한다.
로지스틱 회귀에 사용되는 가장 대표적인 함수가 시그모이드이다. 시그모이드의 수식과 그래프 형태는 아래와 같다.


시그모이드 함수의 특징은 아래와 같다.
- 로지스틱 함수는 0과 1사이의 값을 출력하는 시그모이드 함수를 사용한다.
- 시그모이드 함수는 binary classification에 사용된다.
- t값이 축의 가운데에 있을때는 Linear한 형태를 갖는다.
- 인풋의 normalization이 잘못되었다면 극단값 0 or 1만 나오거나 너무 Linear한 모델을 갖는다.
- 위 문제를 해결하기 위해서 다양한 activation function을 사용한다.
로지스틱 회귀 모델은 아래와 같은 방식으로 이진 분류한다.

훈련과 비용함수
이제 로지스틱 회귀 모델이 어떻게 확률을 추정하고 예측하는지 알았다. 그럼 이제 로지스틱 회귀 모델을 훈련시키는 방법에 대해 알아보자. 훈련의 목적은 양성 샘플(y=1)에 대해서는 높은 확률을 추정하고 음성 샘플(y=0)에 대해서는 낮은 확률을 추정하는 모델의 파라미터 벡터 w를 찾는 것이다.
만약 선형 회귀와 같은 방식으로 손실함수를 계산하면 아래와 같은 non-convex한 그래프가 나온다.

이러한 그래프에서 경사 하강법을 사용하면 local minimum에 빠질 위험이 크기 때문에 경사 하강법을 적용할 수 있는 매끈하고 오목한 형태를 만들어 주어야 한다.
로지스틱 회귀 모델에서 하나의 훈련 샘플에 대한 손실함수는 아래와 같이 표현할 수 있다.

양성 샘플의 경우 p가 0에 가까워질수록 비용이 크게 증가할 것이다. 음성 샘플의 경우에도 p가 1에 가까워질 수록 비용이 크게 증가한다는 점을 알 수 있다. 위 조건식을 하나의 식으로 합칠 수 있다.
전체 훈련 세트에 대한 비용 함수는 모든 훈련 샘플의 비용을 평균한 것이다. 이를 로그 손실이라고 부르며 아래처럼 하나의 식으로 쓸 수 있다.

이 비용함수는 볼록 함수이므로 경사 하강법의 전역 최솟값을 찾는 것이 가능하다. 이 비용 함수의 j번째 모델 파라미터 Wj에 대해 편미분 하면 다음과 같은 식을 얻을 수 있다.

이 식은 각 샘플에 대해 예측 오차를 계산하고 j번째 특성값을 곱해서 모든 훈련 샘플에 대해 평균을 낸다.
모든 편도함수를 포함한 그레이디언트 벡터를 만들면 배치 경사 하강법 알고리즘을 사용할 수 있다.
logx/dx = 1/x
sig/dt = sig(1-sig)
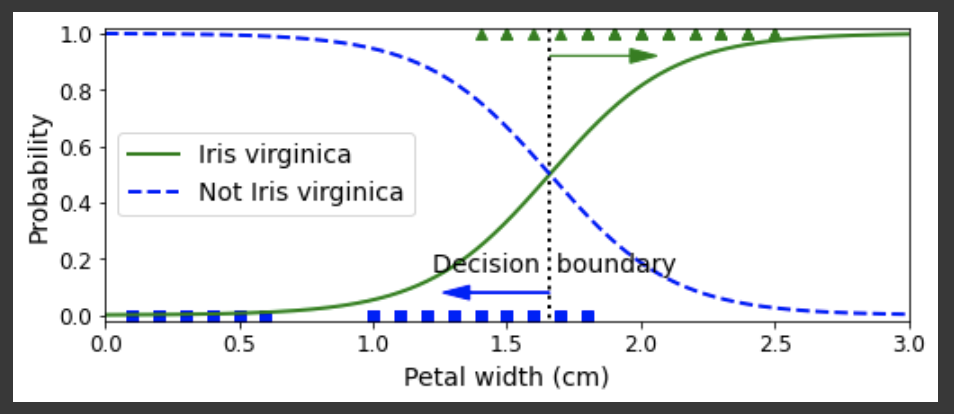
결정경계란 아래 도표의 점선과 같이 Yes / No를 판가름하는 경계를 의미한다.
소프트맥스 회귀(Softmax Regression) / 다항 로지스틱 회귀(Multinomial logistic regression)
로지스틱 회귀 모델은 여러 개의 이진 분류기를 훈련시켜 연결하지 않고 직접 다중 클래스를 지원하도록 일반화될 수 있다. 이를 소프트맥스 회귀 혹은 다항 로지스틱 회귀라고 한다.
개념은 매우 간단하다. 샘플 x가 주어지면 먼저 소프트맥스 회귀 모델이 각 클래스 k에 대한 점수 sk(x)를 계산하고, 그 점수에 소프트맥스 함수 또는 정규화된 지수 함수를 적용하여 각 클래스의 확률을 추정한다. sk(x)를 계산하는 방식은 선형 회귀 예측과 매우 비슷하다.
각 클래스는 자신만의 파라미터 백터 Wk가 있다. 이 벡터들은 파라미터 행렬에 행으로 저장된다.
샘플 x에 대해 각 클래스의 점수가 계산되면 소프트맥스 함수를 통과시켜 클래스 k에 속할 확률을 추정할 수 있다. 이 함수는 각 점수에 지수 함수를 적용한 후 정규화한다. 일반적으로 이 함수를 로짓 또는 로그-오즈라고 부른다.

식에서 exp는 확률을 표현하기 위해 사용한다. 또한 다 더했을 때 1이 되게 하는 normalization이 적용되었다.
로지스틱 회귀 분류기와 마찬가지로 스프트맥스 회귀 분류기는 추정확률이 가장 높은 클래스를 선택한다.

위 식은 argmax안의 식이 최대가 되도록 하는 인자 k를 의미한다. 즉 확률이 가장 높은 값의 인덱스가 예측결과가 되는 것이다.
소프트맥스 회귀 분류기는 한 번에 하나의 클래스만 예측한다. (mullticlass not multiinput) 따라서 상호 배타적인 클래스에서만 사용하며 하나의 사진에서 여러 사람의 얼굴을 인식하는 데는 사용할 수 없다.
소프트맥스 회귀 / 다항 로지스틱 회귀에서는 손실함수로 크로스 엔트로피 함수를 사용한다.

딱 두 개의 클래스가 있을 때(k=2) 이 손실 함수는 로지스틱 회귀의 손실 함수와 같다.
'Deep Learning' 카테고리의 다른 글
| 0206 Vanishing / Exploding Gradient (0) | 2022.04.17 |
|---|---|
| 0204 Cross Validation / Confusion Matrix (0) | 2022.04.12 |
| 0202 Regularized Linear Models (0) | 2022.04.12 |
| 0201 Regression Model (0) | 2022.04.12 |
| 딥러닝 01::퍼셉트론에서 손실함수 까지 (0) | 2022.03.22 |



